Forschungsprozess
Wie bereits im vorangegangenen Kapitel angemerkt, ist der Sekundäranalyse ein eigenes Forschungsdesign zu attestieren, welches sich von Projekten mit eigener Primärerhebung teilweise aber zugleich bedeutend unterscheidet. Zur Veranschaulichung sind in Abbildung 1 der in vielen Büchern über die empirische quantitative Sozialforschung (u.a. Kromrey, Roose, & Strübing, 2016, S. 70; Hug & Poscheschnik, 2015, S. 67; Bryman, 2012, S. 151) beschriebene und auf eine Primärerhebung abzielende Forschungsprozess – im Nachfolgenden als „klassischer Forschungsprozess“ bezeichnet – sowie der Forschungsprozess einer Sekundäranalyse gegenübergestellt. Zentraler Unterschied liegt in der Datenbeschaffung begründet, hat damit aber auch Einfluss auf vorangegangene Schritte. Vereinfacht formuliert lässt sich die idealtypische Linearität des klassischen Forschungsprozesses in der Praxis der Sekundäranalyse nicht aufrecht halten und ist verstärkt durch Wechselwirkungen geprägt. Diese Aussage ist jedoch in zweierlei Hinsicht zu relativieren:
a. Prämisse – Die Sekundäranalyse ist nicht Konsequenz, sondern ursprünglich intendiert.
Diekmann (2002) oder Schnell (2012) verweisen darauf, dass eine Sekundäranalyse durchgeführt werden kann (bzw. sollte), wenn passende Sekundärdaten vorhanden sind. In diesem Fall ist die Sekundäranalyse eine Konsequenz verfügbarer und passender Daten, womit sich zwar die Datenbeschaffung ändert, jedoch das lineare Vorgehen weitgehend beibehalten wird. Ist hingegen bereits von Beginn an eine Sekundäranalyse intendiert – weil etwa die Ressourcen einer Erhebung grundsätzlich nicht zur Verfügung stehen –, dann bedarf es eines Arrangements mit den vorhandenen Daten. Hierzu nochmals Roose (2013, S. 703). „Die Primäranalyse kann die besten realisierbaren Indikatoren nutzen, die Sekundäranalyse nur die besten verfügbaren Variablen“; dies leitet zur zweiten Prämisse über.
b. Prämisse – Die Sekundäranalyse ist theoriegeleitet.
Auch wenn eine Sekundäranalyse ursprünglich intendiert ist, so darf nicht der Fehler begangen werden, sich theorielos auf das Vorhandensein von Daten bei der Verwendung dieser zu berufen. Die Interdependenz zwischen Forschungsfrage (anschließender Operationalisierung usw.) und vorhandener Daten ist als ein Balanceakt zwischen Verfügbarkeit und theoretischer Fundierung zu verstehen. Sind die Einschränkungen aus der Datengrundlage zu groß, so lässt sich das Projekt auf Basis von Sekundärdaten eben nicht durchführen bzw. muss das Forschungsvorhaben neu ausgerichtet werden. Die Möglichkeit der Verschränkung findet entlang der Aufrechterhaltung inhaltlicher Validität ihre Grenzen.
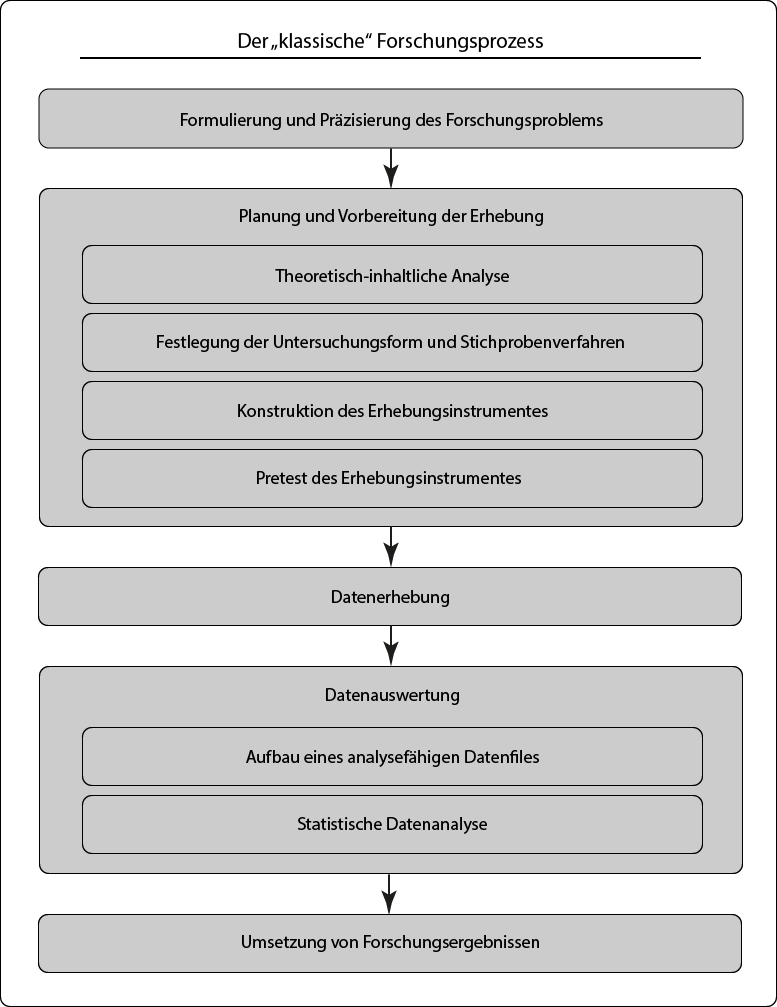
Abbildung 1 - Klassischer Forschungsprozess
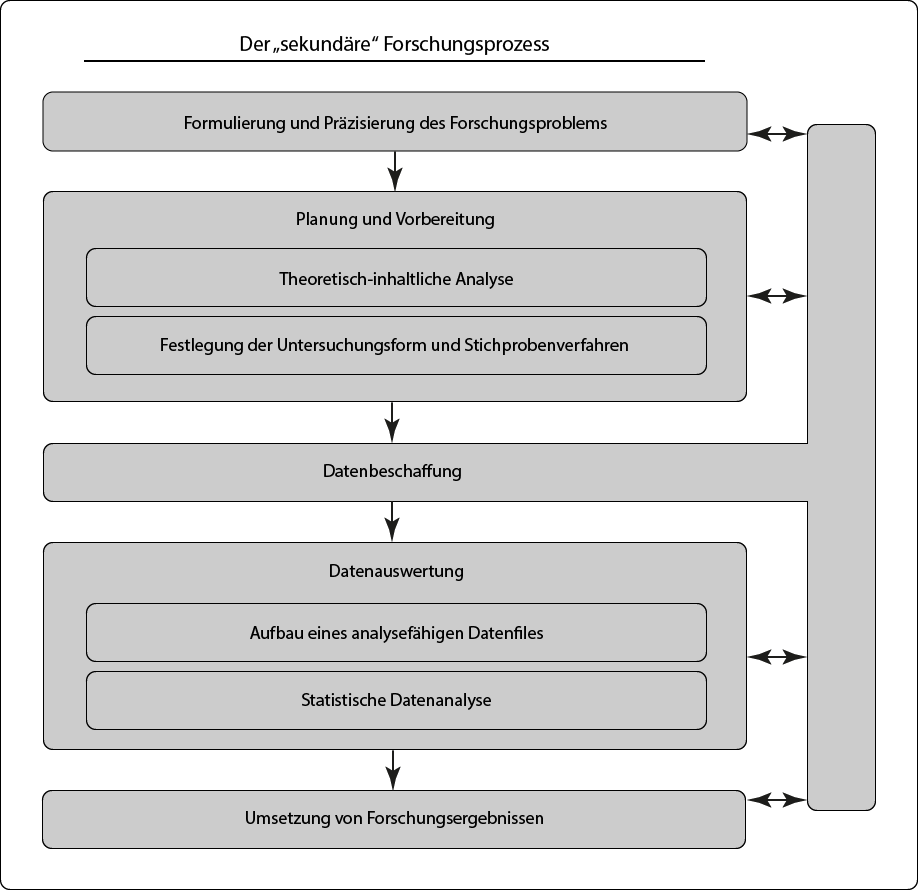
Abbildung 2 - Sekundärer Forschungsprozess
Am Anfang eines jeden Forschungsvorhabens steht das Forschungsproblem bzw. die Frage, was überhaupt untersucht werden soll. Der Entstehungszusammenhang reicht von wissenschaftlichem (oder persönlichem) Interesse, über die Auftragsvergabe (jemand möchte ein bestimmtes Phänomen beforscht haben) bis hin zu auferlegten Themensetzungen (wie bei Qualifikationsarbeiten nicht unüblich). Zur Themenfindung lassen sich aber auch Kreativtechniken (siehe etwa Jost & Richter, 2015) einsetzen, aus einem Literaturstudium können Forschungslücken bzw. zumindest erneut zu prüfende Fragestellungen abgeleitet oder in Lehrveranstaltungen behandelte Themen wieder aufgriffen werden. Letztendlich ist weniger der Ursprung der Idee entscheidend, als eine meist zu Beginn noch sehr offene Problemstellung auf eine Forschungsfrage und für quantitative Arbeiten üblich, diese zusätzlich in eine oder mehrere Hypothesen zu konkretisieren. „In der Sozialforschung ist eine Hypothese eine theoretisch begründet Aussage über den Zusammenhang zwischen zwei oder mehr Variablen, die empirisch untersucht werden soll“ (Schirmer, 2009, S. 125). Sie stellen damit ein Bindeglied zwischen Theorie und Empirie dar und lassen sich entweder rein aus Theorien ableiten (deduzieren) oder basieren auf (selbst)entwickelten und dennoch theoriegeleiteten „Mini-Theorien“ bzw. (Survey-)Modellen (Kromrey u. a., 2016, S. 96). Eine theoretische Fundierung erfährt die Arbeit zudem in der Aufbereitung des Forschungsstandes, welcher auch die Einbettung von Erkenntnissen vorangegangener empirischer Untersuchungen zum Thema enthält. Selbst bei explorativen Studien nähert man sich dem Forschungsgegenstand meist nicht theorielos an, da zumindest zu Teilaspekten bereits Annahmen in der Wissenschaft bestehen dürften. Zusammenfassend bedeutet die Entwicklung von Forschungsfragen und Hypothesen, sich in die bestehende Literatur einzuarbeiten und mit dem gewonnenen Wissen das Forschungsproblem zu präzisieren. Entsprechend ist dieser Phase ausreichend Zeit einzuräumen.
Die Forschungsfrage bzw. vor allem die Hypothesen bestimmen wesentlich die weitere Planung etwa hinsichtlich der Untersuchungsebene (Kollektiv- und/oder Individualeben), der benötigten Daten resultierend aus der Erhebungsform (Querschnitts-, Trend-, oder Panelerhebung) oder der Zielpopulation über welche Erkenntnisse gewonnen werden sollen (Diekmann, 2002, S. 194). Im Umkehrschluss bedeutet dies, dass die Entwicklung von Forschungsfrage und Hypothesen von der Verfügbarkeit der Sekundärdaten gerahmt wird. Neben dem Literaturstudium gilt es daher, bereits potentielle Sekundärdatensätze zu eruieren. Je nach Themenfeld können sich mehrere Datensätze anbieten. In solch einem Fall lässt sich die Entscheidung im Sinne der bestmöglichen Passung (siehe weiter unten) später treffen. Auf der anderen Seite kann die Datenlage so begrenzt sein, dass sich gewisse Forschungsfragen nicht adäquat beantworten lassen. In solch einem Fall könnte etwa die Abkehr von einer Längsschnittbetrachtung hin zu einer Querschnittsbetrachtung oder die Ausweitung der Untersuchungspopulation (anstatt ältere Menschen aus Wien zu beforschen, werden nun ältere Menschen aus Österreich in den Blick genommen) zur Ausdehnung des Samples eine mögliche Konsequenz sein. Mit Sekundärdaten zu arbeiten bedeutet, wissenschaftlich vertretbare Kompromisse zu finden, welche sich bereits in der Formulierung der Forschungsfrage bzw. Hypothesen äußert.
Mit der Formulierung der Forschungsfrage und Hypothesen gelangt man zu der Frage, was gemessen bzw. analysiert werden soll. Forschungsfrage bzw. Hypothesen enthalten theoretische Konzepte/Konstrukte bzw. Begriffe, die „mit der beobachtbaren Erfahrungswirklichkeit verknüpft werden müssen“ (Döring & Bortz, 2016, S. 222). Solche, als komplex zu bezeichnende Begriffe wie etwa Arbeitszufriedenheit oder Lebensqualität mögen im alltäglichen Gebrauch als unmissverständlich angesehen werden. Reflektiert man diese, wird die diffuse Beschaffenheit schnell bewusst. Sind es das Einkommen, die Gesundheit oder der verfügbare Wohnraum, welche Lebensqualität neben vielen weiteren Dimensionen konstituieren bzw. damit in Zusammenhang stehen? Geht es um die subjektive Bewertung der eigenen Lebensumstände oder eher um objektivierte Faktoren? Soll unter Einkommen der Brutto- oder Nettobetrag, abzüglich Alimentation und zuzüglich von monetären Sozialtransfers definiert sein und was ist unter Gesundheit genau zu verstehen? Zur Beantwortung dieser Fragen wird eine theoretisch-inhaltliche Analyse durchgeführt, womit man zur Konzeptspezifikation und anschließend der Operationalisierung gelangt (siehe auch Paier, 2010). Beide Begriffe werden in der Literatur nicht immer getrennt behandelt bzw. umgekehrt, in manchen Fällen gar synonym gebraucht. Richtig ist, dass sich beide Schritte aufeinander beziehen, trotzdem ist es sinnvoll, diese gedanklich voneinander zu trennen (siehe Abbildung 3).
Mittels Konzeptspezifikation werden theoretische Konzepte bzw. Begriffe expliziert, also Aspekte bzw. Dimensionen herausgearbeitet, welche das Konstrukt präziseren (Nominaldefinition) und einen Konnex zu beobachtbaren Sachverhalten herstellen.
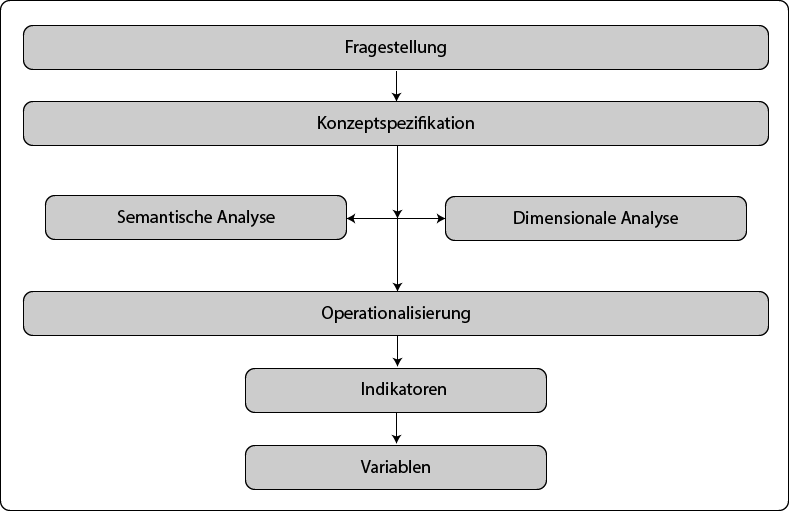
Abbildung 3 – Theoretisch-inhaltliche Analyse
Zwei Ebenen lassen sich bei der Konzeptspezifikation unterscheiden: die semantische und die dimensionale Analyse. Mittels ersterer wird die Bedeutung eines Begriffes erschlossen, während auf Basis letzterer die Eigenschaftsdimensionen eines Begriffs herausgearbeitet werden. Beiden ist nach Kromrey, Roose, & Strübing (2016, S. 141) gemein, dass der Sachverhalt bzw. Begriff gedanklich eine Strukturierung und Präzisierung erfährt, jedoch an zwei unterschiedlichen Ausgangspunkten ansetzen und trotzdem ineinander überführen. Die dimensionale Analyse setzt vorrangig bei einem empirischen Phänomen an, für welches zuerst Beobachtungsdimensionen herausgearbeitet und selektiert werden, um diese Dimensionen anschließend in Beziehung zu setzen und mit sprachlichen Zeichen (Definition des Begriffs) zu verknüpfen. D.h. ein Phänomen oder Gegenstand wird in seinen empirischen Eigenschaften erfasst und sprachlich strukturiert. Ausgangspunkt der dimensionalen Analyse ist also ein empirischer Sachverhalt mit dem Ziel der Formulierung eines (empirisch-)theoretischen Modells. Mit der semantischen Analyse startet man hingegen, wenn bereits Theorien oder Definitionen bzw. wissenschaftliche Aussagen über empirische Sachverhalte bestehen und einerseits zu klären gilt, welche Bedeutung diese Aussagen haben und welche empirischen Sachverhalte diesen Bedeutungsdimensionen entsprechen. Zusammengefasst ist der Ausgangspunkt der semantischen Analyse die Theorie mit dem Ziel eines (theoretisch-)empirischen Modells.
Forschungspraktisch gehen beide Verfahren Hand in Hand, im Besonderen, wenn man sich einem persönlich noch unbekannten Themenfeld zuwendet. Zur vereinfachten Handhabung soll der dimensionalen, wie semantischen Analyse jeweils eine Funktion zugewiesen werden:
Semantische Analyse |
Dimensionale Analyse |
|---|---|
Funktion: Im Zuge der semantischen Analyse geht es darum, die Bedeutung von Begriffen zu erfassen und jene für das eigene Forschungsprojekt passende Bedeutung(en) auszuwählen. |
Funktion: Im Zuge der dimensionalen Analyse geht es darum, Beobachtungsdimensionen herauszuarbeiten, welche sich mit der untersuchungsrelevanten Bedeutung eines Begriffs verknüpfen lassen. |
Forschungspraktische Konsequenz: Was ist also gemeint, wenn in der Hypothese bspw. von Gesundheit gesprochen wird? Durch ein Literaturstudium zeigt sich, dass Gesundheit – verkürzt dargestellt – etwa die Abstinenz von Erkrankungen und/oder funktionale Einbußen bedeuten könnte. |
Forschungspraktische Konsequenz: Welche Dimensionen liegen der Abstinenz von Erkrankungen und funktionalen Einbuße zugrunde? |
Beispiel:
|
Beispiel: Welche Dimensionen lassen sich dem Begriff unter Berücksichtigung seiner Bedeutungen zuordnen?
|
Tabelle 1 – Konzeptspezifikation
Zum Schluss der Konzeptspezifikation werden jene Bedeutungen und Dimensionen ausgewählt, welche für das Forschungsvorhaben vor dem Hintergrund der Forschungsfrage von Relevanz sind und sich logisch bzw. theoretisch integrieren lassen. „Die Selektion ist anhand begründeter und intersubjektiv nachprüfbarer Kriterien vorzunehmen; die Begründungen sind zu dokumentieren“ (Kromrey u. a., 2016, S. 120).
Mittels Operationalisierung wird bestimmt, anhand welcher Indikatoren das theoretische Konzept bzw. dessen Dimensionen erfass- und messbar gemacht werden soll (operationale Definition).
Die Resultate dieses Überlegungsprozesses werden auch als Korrespondenzregeln bezeichnet. „Sie legen fest, welcher beobachtbare Sachverhalt als Hinweis (als ‚Indikator’) auf den theoretisch gemeinten Sachverhalt gelten soll, oder mit anderen Worten: welcher empirische Sachverhalt mit dem theoretischen Sachverhalt ‚korrespondiert’. Korrespondenzregeln nehmen also die Zuordnung von Indikatoren zu Begriffen vor“ (Kromrey u. a., 2016, S. 184). Hiermit schließt man an die erarbeiteten und ausgewählten Dimensionen der Konzeptspezifikation an. Einerseits mag es Dimensionen geben, welche direkt als Indikatoren interpretiert werden können, wie etwa die „Anzahl an chronischen Erkrankungen“, welche eine befragte Person zum Befragungszeitpunkt wissentlich hat. Andererseits müssen etwa für den Bereich der Mobilität bzw. deren Unterdimensionen Indikatoren erarbeitet werden. D.h., mittels welcher (manifesten) Indikatoren lässt sich die (latente) funktionale Mobilität erfassen bzw. beobachten? Entsprechend der WHO ICF ließen sich folgende Indikatoren andenken (auch diese sind für eine kompakte Darstellung verkürzt und könnten um weitere Unterdimensionen und Indikatoren ergänzt werden):
Unterdimensionen |
Indikatoren |
Mögliche Items |
|---|---|---|
Körperposition |
In elementare Körperposition wechseln Konkretisierung: Seine Körperposition in eine liegende, kniende, hockende, sitzende oder stehende Position ändern |
Hatten Sie in den letzten 7 Tagen Schwierigkeiten: ... sich auf einen Stuhl zu setzen und wieder aufzustehen? ... sich zu bücken und einen Gegenstand aufzuheben? |
|
In einer Körperposition verbleiben Konkretisierung:In einer oben genannten Körperposition für eine bestimmte Zeit verbleiben |
Hatten Sie in den letzten 7 Tagen Schwierigkeiten: ... über längere Zeit ohne Unterbrechung zu stehen (z.B. 20 Minuten in einer Warteschlange)? ... über längere Zeit auf einem Stuhl zu sitzen (z.B. für die Dauer des Essens)? |
|
|
Eigenständige Fortbewegung |
Gehen Konkretisierung: Sich zu Fuß auf einer Oberfläche Schritt für Schritt fortbewegen |
Hatten Sie in den letzten 7 Tagen Schwierigkeiten, ohne Hilfsmittel (wie z.B. Gehhilfen): ... Entfernungen innerhalb eines Gebäudes (bis 200 Meter) zu gehen? |
Tabelle 2 – Operationalisierung
Exemplarisch ist die Unterdimension „Körperposition “ herausgegriffen, welche auf die Basisfunktion der körperlichen Mobilität abzielt. Zentral sind hierbei die Indikatoren, ob man überhaupt eine Körperposition einnehmen (jeweils ein Indikator für Liegen, Knien, Hocken, Sitzen, Stehen) und ob man in dieser für eine gewisse Zeit verbleiben kann (jeweils ein Indikator für die Verweildauer). Der Unterdimension „eigenständige Fortbewegung“ wurde nur ein Indikator zugewiesen, natürlich ließe sich auch an den Indikator „Laufen“ denken. Laufen und Gehen ließen sich daher als Indikatoren der Unterdimension „Bewegung zu Fuß“ subsummieren:
Gesundheit -> Funktionale Aspekte -> Mobilität -> Eigenständige Fortbewegung -> Bewegung zu Fuß -> Indikator zu Gehen und Indikator für Laufen
Ob dies nötig oder sinnvoll ist – eine vollständige Erfassung eines Sachverhaltes wird bereits aus Zeitgründen meist nicht möglich sein –, ist einerseits im Kontext der Forschungsfrage zu beantworten und andererseits eine logisch-theoretische Überlegung. Wer Schwierigkeiten hat beim Gehen, wird in den meisten Fällen auch Schwierigkeiten haben beim Laufen. Zielt die Forschungsfrage daher nicht explizit auf die Fortbewegung des Laufens ab, dürfte der Indikator „Gehen“ genügen, um etwas über die eigenständige Fortbewegungsmöglichkeit einer Person zu erfahren. Bedeutender erscheint vielmehr der Einbezug der räumlichen Distanz in die Überlegung, denn nur wer auch eine gewisse Strecke gehen kann (etwa 200 Meter) dürfte in der Lage sein bspw. einen Supermarkt zu erreichen. Die Konkretisierung lässt sich daher wie folgt formulieren: „Die Fähigkeit des Gehens soll bedeuten, sich zu Fuß auf einer Oberfläche Schritt für Schritt zumindest 200 Meter fortzubewegen“ und soll mittels Frage (Item) über eine Selbsteinschätzung durch die Befragten auf einer 5-teiligen Skala beantwortet werden.
In der rechten Spalte der Tabelle 2 sind Beispiele aus dem MOSES-Fragebogen (siehe Farin, Kosiol, & Fleitz, 2008) angegeben, wie ein Teil der Indikatoren über Items abgebildet werden könnte. Die Antworten einer Person ließen sich anschließend zu einem Index summieren, welcher sich als ein Maß für die Mobilitätfähigkeiten einer Person behandeln lässt. Neben anderen möglichen Formulierungen der Items ist zu bedenken, dass es sich in dieser Form um Selbsteinschätzungen handelt. Die Daten könnten aber auch durch einen anderen Modus, etwa mittels medizinischem Gutachten gewonnen werden. Auch wenn sich in diesem Abschnitt nicht näher darauf eingehen lässt, so muss dem Modus und der Frageformulierung von Items hohe Bedeutung in der Genese von Daten beigemessen werden. Ein paar Denkanstöße: Hat der Bezugszeitraum „in den letzten 7 Tagen“ womöglich Einfluss auf die Antworten? Sollte anstatt einer negativen Formulierung „Schwierigkeiten“ eine positive gewählt werden? Sind die Fragen für die Zielgruppe verständlich und alltagstauglich? Wie sollten die Antwortkategorien (4, 5, 6 usw. Antwortmöglichkeiten) ausgestaltet sein? Auch bei der Nutzung von Sekundärdaten muss der Genese der Daten hohe Beachtung zukommen, um bspw. Frage-Bias in die Reflexion der gewonnenen Ergebnisse einzubeziehen.
In Abbildung 3 sind die Variablen den Indikatoren nachgereiht, hierzu noch eine kurze Erörterung. Zuvor aber auch in diesem Fall der Hinweis, dass der Begriff unterschiedlich in Verwendung ist. Häufig wird der Begriff „Variable“ den Begriffen bzw. Konstrukten einer Hypothese gleichgesetzt. Lebensqualität wird also als Variable begriffen. Arbeitet man mit Sekundärdaten bzw. konkret mit dem Datenfile, empfiehlt es sich im statistischen Sinn, eine Variable als Merkmal von Merkmalsträgern, die mehrere Ausprägungen hat, zu definieren. Der Indikator Alter kann daher durch unterschiedliche Variablen repräsentiert werden: etwa das Geburtsdatum oder das aktuelle kalendarische Alter – beide Variablen könnten im Datensatz auffindbar sein (wie es etwa bei easySHARE der Fall ist). Einmal handelt es sich um das Merkmal Geburtsdatum und einmal um das Merkmal kalendarisches Alter. Obwohl beide unterschiedliche Ausprägungen desselben Merkmalträgers (Person) aufweisen, bilden beide den Indikator Alter ab (wenn auch mit etwas unterschiedlichem Informationsgehalt). Im Mikrozensus gibt es als ein weiteres Beispiel zumindest zwei Variablen, welche den Indikator Erwerbsstatus repräsentieren. Einmal als Resultat einer Selbsteinschätzung und einmal nach dem ILO-Konzept („Demnach gelten Personen als erwerbstätig, wenn sie in der Referenzwoche – die Woche vor dem Befragungszeitpunkt – mindestens eine Stunde gearbeitet oder wegen Urlaub, Krankheit et cetera nicht gearbeitet haben, aber normalerweise einer Beschäftigung nachgehen“).
Am Beispiel von Gesundheit wurde der Prozess der Konzeptspezifikation bis zur Operationalisierung nachgezeichnet und lässt sich zusammenfassend in nachfolgender Abbildung 4 visualisieren:
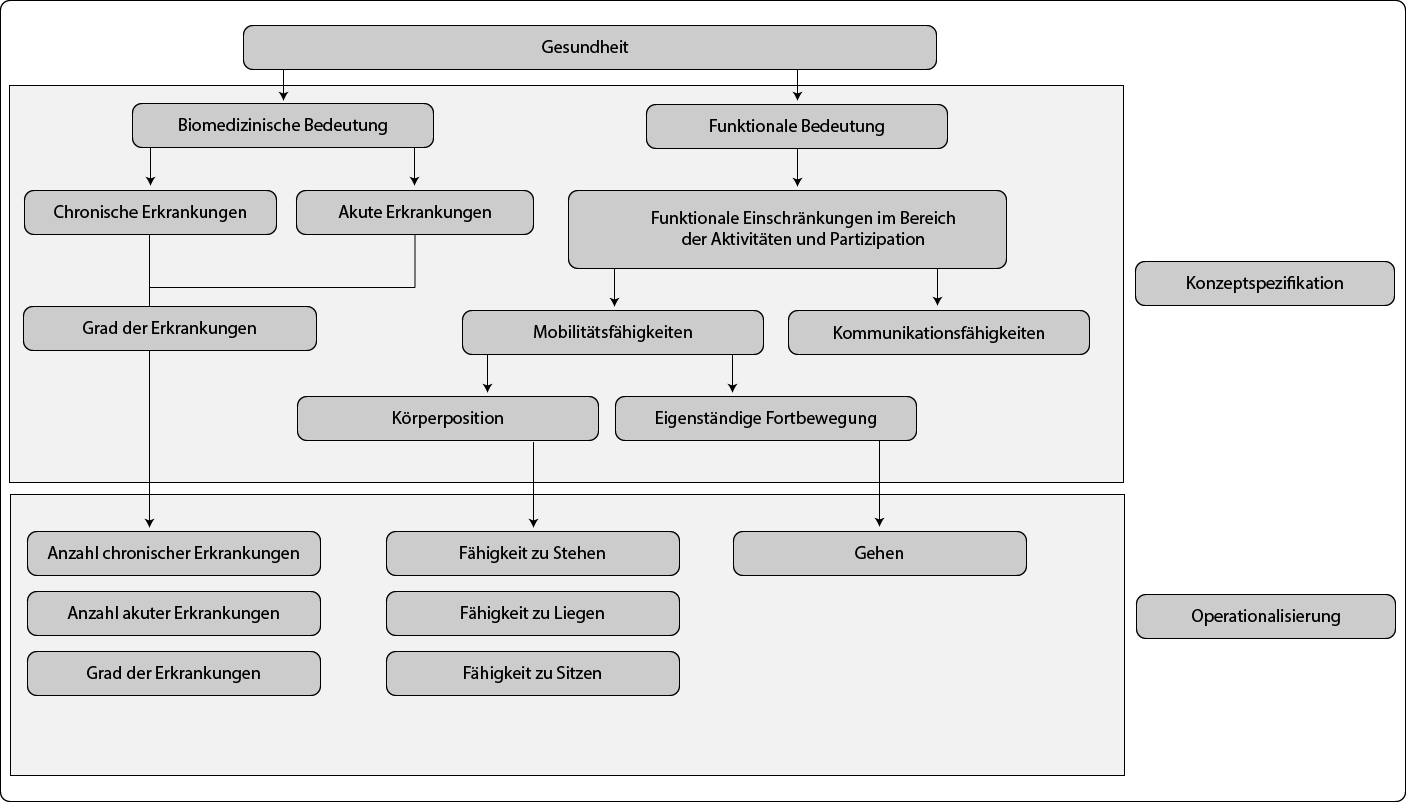
Abbildung 4 – Beispiel einer theoretisch-inhaltlichen Analyse
Nochmals sei betont, dass viele Dimensionen und mögliche Indikatoren in diesem Beispiel (Abbildung 4) nicht berücksichtigt wurden; je umfangreicher solch eine Systematisierung ausfällt, umso leichter ist es, die am besten realisierbaren Dimensionen und Indikatoren auszuwählen. Die Visualisierung hilft zudem Zusammenhänge zu entdecken, welche sich wiederum in Hypothesen formulieren lassen – auch wenn diese nicht in der Arbeit geprüft werden, so sind sie Teil der theoretischen Argumentation. Unschwer lässt sich erkennen, dass die Anzahl und der Grad von Erkrankungen im Zusammenhang mit der Mobilitätsfähigkeit stehen dürfte. In einer Hypothese formuliert: „Je mehr chronische und akute Erkrankungen eine Person hat, desto geringer ist ihre körperliche Mobilität“ und „Je höher der Grad an Erkrankungen, desto geringer ist die körperliche Mobilität“. Führt man den Gedanken noch etwas aus, so liegt der logische Schluss nahe, dass dies nicht die einzigen Faktoren sein werden, welche auf die körperliche Mobilität einen Einfluss haben. Bspw. persönliche Bewältigungsstrategien, Hilfsmittel oder das persönliche Schmerzempfinden dürften ebenso auf die Mobilitätsfähigkeiten einwirken. Eine perfekte Korrelation ist a priori unwahrscheinlich, interessant ist aber die Frage, wie stark der Zusammenhang trotz dieser Vernachlässigungen ausfällt.
Phase 1 und Phase 2 des Forschungsprozesses sind sehr eng miteinander verwoben und teils zirkulär organisiert. Einerseits leiten die Forschungsfrage bzw. Hypothesen die Konzeptspezifikation und Operationalisierung an, andererseits könnten im Zuge dieser Arbeitsschritte Hypothesen noch eine weitere Präzisierung erfahren. Zentral ist, am Ende der zweiten Phase mit logischen, theoriegeleiteten und überprüfbaren Hypothesen zu arbeiten, welche anhand gut korrespondierender Indikatoren eine empirische Überprüfung finden sollen.
Im Zuge der theoretisch-inhaltlichen Analyse tritt die Verschränkung mit potentiellen Sekundärdaten hervor und bedarf spätestens jetzt einer intensiven Auseinandersetzung, welche Daten tatsächlich zur Verfügung stehen und wie diese gewonnen wurden. Einerseits wird hierzu die Dokumentation des Surveys bzw. einzelner Befragungen herangezogen (Codebücher, Berichte über die Methode usw.), andererseits ist es lohnenswert das Erhebungsinstrument – in den meisten Fällen den Fragebogen – zu begutachten. Mittels letzterem lässt sich ein schneller Überblick gewinnen, welche Fragen (Items) konkret zu einem Thema gestellt wurden und welche Antwortmöglichkeiten den Befragten zur Verfügung standen. Durch diesen praktischen Zugang ist nicht nur eine inhaltliche Bestimmung, sondern eine Reflexion der Qualität von einzelnen Items (etwa ob diese eindeutig und unmissverständlich sind) und deren Antwortmöglichkeiten (etwa ob diese disjunkt sind) möglich. Je nach Gestaltung des Fragebogens lassen sich des Weiteren die Bedingungen für einzelne Fragen (ob bspw. Filterfragen gesetzt wurden) nachvollziehen. Die Dokumentation informiert unter anderem über die Untersuchungsform, Sampleverfahren sowie die tatsächliche Stichprobengröße. In manchen Fällen sind „quality reports“ anhängig bzw. wird näher auf die Konstruktion der Befragung eingegangen. Die Codebücher veranschaulichen die Codierung der Antwortkategorien, d.h. sie geben Auskunft über die Zahlenwerte der einzelnen Antwortmöglichkeiten.
Durch die Auseinandersetzung mit den genannten Materialien wird ersichtlich, welche die verfügbaren Indikatoren bzw. Variablen („Ist-Variablen“) sind und sollten den „best-möglichen“ Indikatoren bzw. Variablen („Soll-Variable“) aus der Konzeptspezifikation und Operationalisierung gegenübergestellt werden. Diese Gegenüberstellung lässt sich als das Passungsverhältnis der Sekundärdaten bezeichnen und bedarf bei Abweichung einer Reflexion über damit einhergehende Folgen. Diese Reflexionsarbeit scheint häufig als Teil der Limitationen bzw. Einschränkungen – wie man sie bei Journalartikel am Schluss der Arbeit findet – in verschriftlichter Form wieder auf. Sie ist also nicht umsonst, sondern wichtiger Teil einer wissenschaftlichen Arbeit.
Abbildung 5 stellt die Ist-Variablen aus SHARE den Soll-Variablen zur körperlichen Mobilität gegenüber.
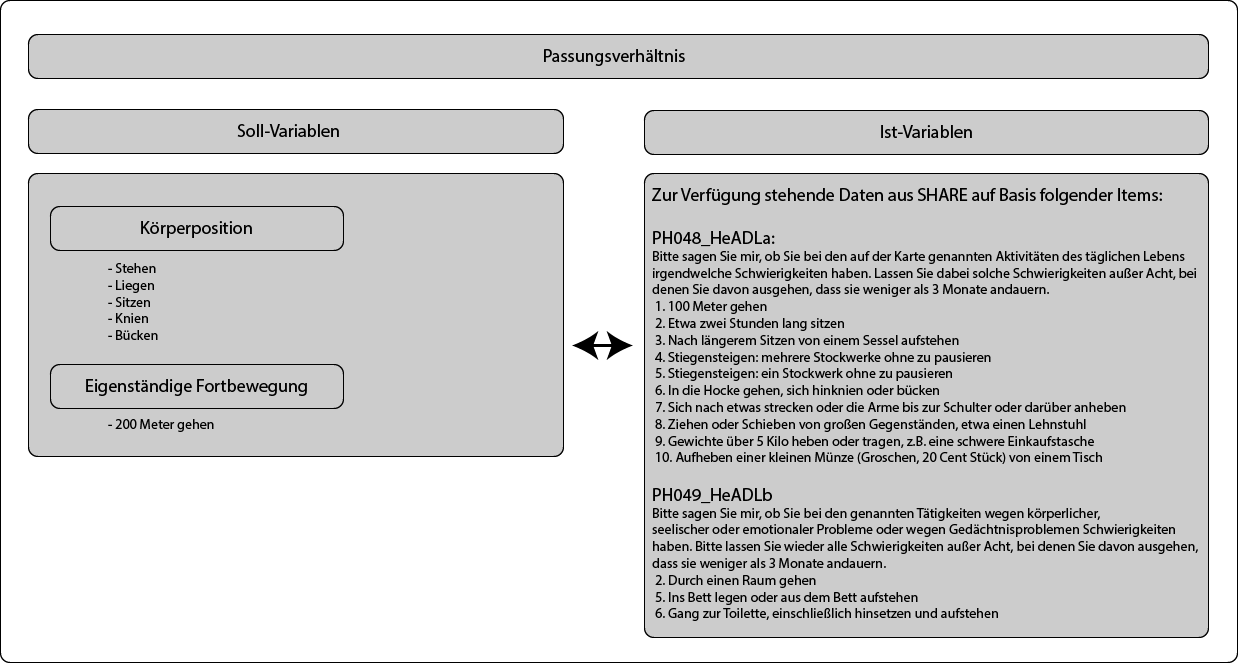
Abbildung 5 - Passungsverhältnis
In diesem Fall lässt sich das Passungsverhältnis als sehr gut bezeichnen, die beabsichtigten Indikatoren finden sich in den zur Verfügung stehenden Daten wieder. Gehen sogar darüber hinaus und ließen damit eine genauere Betrachtung zu. Beispielsweise wäre es möglich, alle oder einige Indikatoren von PH048 zu einem Index zusammenzufassen und als Index der Mobilitätsfähigkeit zu behandeln. Bei dem Indikator „200 Meter gehen“ muss jedoch eine Einschränkung in Kauf genommen werden, so wurde in PH048 nach der Möglichkeit „100 Meter zu gehen“ gefragt. Inwiefern dies eine Rolle spielt, hängt aber vor allem von der Forschungsfrage und den Hypothesen ab.
Beispiel: Gesundheit und Erreichbarkeit -Phase 1 und Phase 2 sollen nun an Hand eines kurzen Beispiels im Kontext von Sekundärdaten zusammengefasst werden
Studien (u.a. Oswald & Konopik, 2015; Saup & Reichert, 1999) konnten zeigen, dass sich der Aktionsradius älterer Menschen immer weiter einengt und auf das unmittelbare Wohnumfeld und die eigene Wohnung konzentriert. Wesentlichen Einfluss hat hierbei die Gesundheit, welche sich als Ausdruck der körperlichen Mobilität fassen lässt. Hierbei stellt sich nun die Frage, inwiefern die körperliche Mobilität die Erreichbarkeit wichtiger Einrichtungen schmälert. Darüber hinaus kommt dem Einkommen bei der Eröffnung von Handlungsspielräumen eine wichtige Rolle zu und dürfte bei der Bewältigung von Mobilitätseinschränkungen (da man sich bspw. kostspielige Gehhilfen oder ein Taxi leisten kann) dienlich sein. Die Forschungsfrage soll daher lauten: „Inwiefern beeinflusst die Gesundheit die Erreichbarkeit von Supermärkten oder Ärzt*Innen vor dem Hintergrund des Einkommens“.
- Hypothese 1: Je schlechter die Gesundheit, umso schlechter die Erreichbarkeit von Supermärkten und Ärtz*Innen
- Hypothese 2: Je höher das Einkommen, umso besser die Erreichbarkeit von Supermärkten und Ärzt*Innen
Gesundheit wurde bereits theoretisch-inhaltlich analysiert und für die Forschungsfrage scheint vor allem die Fähigkeit zu Gehen von Relevanz. Die Anzahl von Erkrankungen dürfte sich hingegen weniger eignen, da Personen trotz Erkrankungen durchaus mobil sein können. Trotzdem könnten wir die Variable berücksichtigen und damit die Annahme eines geringeren Zusammenhangs prüfen. Zudem ließen sich alle Indikatoren von PH048 zu einem Index zusammenfassen, da alle Bereiche in Summe eine Rolle für die Mobilität spielen dürften (eine durchgeführte Faktorenanalyse auf Basis der SHARE Daten legt dieses Vorgehen nahe), andererseits muss man nicht unbedingt in die Hocke gehen können, um einen Supermarkt (unter normalen Bedingungen) zu erreichen. Aus inhaltlichen Standpunkten ließe sich daher auch eine Reduktion auf PH048 – 1, 4 und 5 – sowie PH049 – 2 – andenken. Hinsichtlich der Erreichbarkeit stehen nur zwei mögliche Variablen zur Verfügung:
- HH028_LocalGroceryShop
Wie leicht ist es, den nächsten Lebensmittelladen oder Supermarkt zu erreichen? (Würden Sie sagen, es ist sehr leicht, leicht, schwierig oder sehr schwierig?) - HH029_LocalGeneralPractitioner
Wie leicht ist es Ihren Hausarzt oder das nächstgelegene Ärztezentrum zu erreichen? (Würden Sie sagen, es ist sehr leicht, leicht, schwierig, sehr schwierig?)
Auf das Einkommen beziehen sich in SHARE mehrere Fragen, welche hier nicht dargestellt werden sollen. Zusätzlich wird ein aus diesen Fragen generiertes Haushaltseinkommen angeboten, welches sich verwenden ließe. Auch hier der Hinweis, dass man sich dem Thema Einkommen in der theoretisch-inhaltlichen Analyse widmen sollte. Weniger wird nämlich das gesamte Einkommen, als das tatsächlich verfügbare Einkommen eine Rolle spielen.
Damit sind alle Komponenten für die Analyse zusammengeführt. Nach Prüfung, ob alle Voraussetzungen für die statistische Analyse erfüllt sind, können die Hypothesen mittels partieller Korrelation mit Einkommen als Kontrollvariable geprüft werden.
Abschließend bedarf es der Rezeption von Döring & Bortz (2016), welche im Kontext der Operationalisierung auf eine zentrale erkenntnistheoretische Einsicht hinweisen:
„Indem die Operationalisierung angibt, über welche Indikatoren und mit welchem standardisierten Messinstrument (z.B. einem standardisierten Fragebogen oder psychologischen Test) ein theoretisches Konstrukt empirisch zu erfassen ist, wird dieses greifbarer. Dabei ist im Auge zu behalten, dass die beobachteten Merkmale keine voraussetzungslosen Tatsachen, sondern immer Ergebnis eines theoretischen Konstruktionsprozesses sind. Der Umstand, dass eine Person auf einem Messinstrument für „Internetsucht“ eine hohe Punktzahl erreicht, bedeutet nicht, dass die Person tatsächlich internetsüchtig „ist“. Es bedeutet, dass ihr Verhalten und Erleben auf der Basis bestimmter theoretischer Vorannahmen mit dem Konzept der Sucht beschrieben und erklärt wird. Internetsucht als reale Tatsache – anstatt als theoretische Konstruktion – aufzufassen, käme einer unzulässigen Verdinglichung bzw. Reifizierung („reification“) gleich. Eine andere Theorie könnte dasselbe Verhalten nicht als „Sucht“, sondern als „Zwang“ oder auch als „Gewohnheit“ auffassen, woraus sich dann andere Schlussfolgerungen hinsichtlich Entstehung oder Behandlung ergeben würden. Empirische Forschung, die gemessene Variablen als Tatsachen auffasst, mündet in einen naiven Empirismus bzw. Positivismus. Deswegen ist die theoretische Konstruiertheit aller wissenschaftlichen Messungen bei der Diskussion von empirischen Forschungsprozessen und ihren Ergebnissen stets zu berücksichtigen. Dies wird im quantitativen Paradigma der empirischen Sozialforschung im Rahmen der Wissenschaftstheorie des Kritischen Rationalismus ausdrücklich betont. Theoretische Konzepte zu operationalisieren läuft somit keineswegs auf ein datengläubiges „empiristisches“ oder „positivistisches“ Vorgehen hinaus, vielmehr verlangt eine seriöse wissenschaftliche Operationalisierung transparente und fundierte theoretische Argumente sowohl bei der Auswahl und Konstruktion von Indikatoren und Messinstrumenten als auch bei der Interpretation der so gewonnenen quantitativen Daten“ (Döring & Bortz, 2016, S. 232).
Nachdem man geklärt hat, was man untersuchen möchte und welche Indikatoren bzw. Variablen dazu benötigt werden, lässt sich das dazu geeignete Design konkretisieren. Bei der Untersuchungsform geht es im Wesentlichen um die Untersuchungsebene und den Untersuchungszeitraum. Zum besseren Verstehen bedarf es einer kurzen Erörterung von Hypothesen, welche als Vermutungen über bestimmte Zusammenhänge gesehen werden können. Neben der Differenzierung „wenn-dann“ und „je-desto“ können Hypothesen in Bezug auf das Aussagefeld unterschieden werden:
- Individualhypothese
- Abhängige und unabhängige Variablen sind Individualmerkmale
- Kollektivhypothese
- Abhängige und unabhängige Variablen sind Kollektivmerkmale
- Kontexthypothese
- Abhängige sind Individualmerkmale und unabhängige Variablen sind Kollektivmerkmale
Zusätzlich lassen sich Hypothesen nach dem Grad der Kausalität unterscheiden:
- Merkmalsassoziation
- Zwischen den Variablen kann zwar ein Zusammenhang, aber keine Kausalität unmittelbar angenommen werden
- Trendhypothese
- Die Zeit nimmt den Platz der unabhängigen Variable ein
- Kausalhypothese
- Es lässt sich eine Ursache-Wirkungs-Relation annehmen
Kurz: die entwickelten Hypothesen verlangen spezifische Daten, welche entlang von Querschnitts-, Trend- oder Panelerhebungen generiert wurden und teils zusätzliche Quellen (etwa über das BIP), welche noch in das Datenfile integriert werden müssen. Wie bereits erörtert wurde, lassen sich Panelerhebungen auch als Querschnittsdaten behandeln, umgekehrt ist dies nicht möglich. Querschnittsbefragungen sind vor allem geeignet für Merkmalsassoziationen, unter Einschränkungen aber auch für Kausalhypothesen (in vielen Fällen bleibt die Annahme von Kausalität aber auf der Ebene einer theoretischen Argumentation verhaftet). Für Trendhypothesen werden Trend- oder Paneldaten benötigt und zur besseren Absicherung von Kausalhypothesen sind Paneldaten zu empfehlen. Aber selbst bei diesen können Störvariablen nicht im Ausmaß eines experimentellen Designs kontrolliert werden, womit alle drei Erhebungsformen unter ex-post-facto Designs fallen; Effekte werden also nur im „Nachhinein“ konstatiert (Döring & Bortz, 2016, S. 201). Zusammenfassend lässt sich zwar ein wenig (von Paneldaten zu Querschnittsdaten) auch die Untersuchungsform in Sekundäranalysen anpassen. In den meisten Fällen müssen aber die Hypothesen entsprechend der vorhandenen Sekundärdaten angepasst werden.
Ähnliches tritt bei der Wahl des Stichprobenverfahrens auf, welches nach Diekmann (2016, S. 192) die Definition der Population, die Art der Stichprobenziehung und den Umfang der Stichprobe umfasst. Selbstredend sind alle drei Bereiche bei Sekundärdaten bereits festgelegt, jedoch muss zwischen der Survey-Population und der Zielpopulation der Forschungsarbeit unterschieden werden. Maximal sind Survey- und Zielpopulation gleich, letztere kann jedoch auch auf eine Teilmenge der Survey-Population festgelegt werden. D.h., während die Survey-Population Personen ab 18 Jahren enthält, interessieren für die Forschungsarbeit nur Personen ab 65 Jahren. Auch in diesem Fall ist eine gewisse Variation innerhalb der Rahmung der Sekundärdaten möglich. Die Art der Stichprobenziehung kann aufgrund von Verzerrungen Einfluss auf die Ergebnisse einer Untersuchung haben und sollte daher – auch wenn sie nicht veränderlich ist – in die Reflexion der Ergebnisse einfließen (zu diesem umfangreichen Thema etwa Diekmann, 2016 oder Kromrey u. a., 2016)
Die Beschaffung des Datensatzes ist zeitlich schwer zu verorten und kann bereits während der Planungsphase hilfreich sein, um sich unter anderem der Fallzahl für das eigene Forschungsvorhaben zu vergewissern. Gemeint ist hierbei, dass ein Datensatz womöglich inhaltlich ein gutes Passungsverhältnis mit der eigenen Forschungsfrage aufweist, jedoch bei Betrachtung einer spezifischen Subpopulation (z.B.: Kinder im Alter von 10-15 Jahren) nur wenige Fälle im Vergleich zur Gesamtstichprobe der Befragung zur Verfügung stehen. Als eine andere Schwierigkeit könnte sich etwa die Verteilung der Antwortkategorien herausstellen, welche andere, (zu Beginn) nicht intendierte statistische Verfahren nötig macht. Solche Informationen lassen sich, abseits von (online) Analysetools (siehe etwa ZACAT) oder der Dokumentation, auf Basis des Datensatzes gewinnen. Viel spricht dafür, möglichst bald an die Beschaffung des Datensatzes zu denken (in Database finden sich zu den vorgestellten Surveys entsprechende Informationen). Auf der anderen Seite kann der Bezug der Daten mit Kosten verbunden sein (auch wenn diese häufig relativ gering sind) oder es sind Datenvereinbarungen (bspw. über die Verwendung, Weitergabe usw.) zu treffen, in welchen vielleicht der oder die Betreuer*In bei Qualifikationsarbeiten als Vertragspartner*In fungieren muss. Die Erfahrung zeigt, dass in der Praxis aufgrund länder- (z.B.: Datenschutzgesetze) und institutionsspezifischer (z.B.: Intentionen zur Weitergabe eigener Daten) Regelungen der Aufwand der Beschaffung variiert, in den meisten Fällen aber ein kostenloser – zumindest unter kleineren Einbußen, wenn nicht alle Daten zur Verfügung gestellt werden – und relativ rascher Bezug möglich ist. Trotzdem sollte man die Bedingungen bereits vorab genau kennen und ein ausreichendes Zeitbudget für die Beschaffung einplanen.
Im Besonderen, wenn der Datenbezug sehr gezielt und ressourcenschonend erfolgen muss, können durch Einbezug von Informationsquellen viele Fragen aufgelöst werden:
Dokumentation der Befragung sondieren
Diese gibt häufig Auskunft über die soziodemographische Verteilung der Stichprobe und im besten Fall sogar über die Fallzahl bei einzelnen Items und die Verteilung der Antworten. Auf Basis der gesamten Dokumentation lässt sich die Struktur der Daten meist gut erfassen.Wissenschaftliche Arbeiten sondieren
Im Kontext bekannter sozialwissenschaftlicher Datensätze findet tendenziell ein reger Publikationsbetrieb statt, womit die Wahrscheinlichkeit hoch ist, dass eine ähnliche Forschungsfrage bereits mit den Daten bearbeitet wurde.Anwenderwissen anderer Forscher*Innen nützen
Student*Innen oder Forscher*Innen im eigenen Umfeld könnten bereits mit dem Datensatz gearbeitet haben.Kontaktaufnahme mit der Institution
Größere Institutionen bieten sogenannte Benützer*innenkonferenzen an, welche über Befragungen bzw. daraus gewonnen Daten bzw. Erkenntnisse informieren. Bleiben nach eingängiger Sondierung der Dokumentation Fragen offen, ist eine gezielte Rücksprache mit Kontaktpersonen des Surveys sinnvoll.
Mit der Beschaffung der Daten geht entlang forschungsethischer Grundprinzipien ein achtsamer Umgang einher. Auf alle Fälle sind die unterzeichneten Datennutzungsbestimmungen einzuhalten bzw. der Datenschutz immer zu gewährleisten.
Nach der Datenbeschaffung beginnt auf empirischer Seite die eigentliche Arbeit, welche zu Beginn meist darin besteht, den Datensatz für die eigene statistische Analyse vorzubereiten. In diesem Schritt geht es also darum, von den „Rohdaten“ zu einem für das Forschungsvorhaben analysefähigen Datenfile zu gelangen. Selbst als „ready to use“ bezeichnete Sekundärdatensätze sind häufig nicht für eine direkte Analyse bereit, müssen Variablen bspw. umcodiert, die Voraussetzungen für statistische Verfahren geprüft, Entscheidungen über Ausreißer getroffen oder Indizes gebildet werden. Die Aufbereitung nimmt häufig mehr Zeit in Anspruch, als die darauffolgende statistische Analyse zur Ergebnisproduktion. Gegenüber einer Primärerhebung entfallen zwar einige Aufgaben – diese können als Datenmanagement bezeichnet werden (wie die Eintragung von Werten in eine Datenmatrix usw.) – und ein paar Optionen sind nicht realisierbar (etwa die Überprüfung von möglichen Eingabefehlern anhand der ausgefüllten Fragebögen), trotzdem gilt, mit großer Sorgfalt die Daten zu prüfen und vorzubereiten. Dies kann entscheidenden Einfluss auf die Ergebnisse der Untersuchung haben. Bei über 600.000 Datenzellen (3.000 Fälle mit 200 Variablen) können Eingabefehler in Sekundärdatensätzen durchaus auftreten (im Besonderen, wenn man mit erst kürzlich veröffentlichten Daten arbeitet). Ein paar Hinweise zum Vorgehen (Akremi, Baur, & Fromm, 2011; Pötschke, 2010; Atteslander & Cromm, 2008), für welches sich SPSS anbiete:
- Überblick der Variablen
- Variablennamen, Variablenbeschriftungen und Datentyp (nummerisch oder string) kennenlernen
- Anzahl der Dezimalstellen prüfen
- Wertebeschriftungen prüfen
- Eingetragenes Messniveau (Skalenniveau) prüfen
- Überblick der Häufigkeiten
- Verteilungsmaße berechnen
- Verteilungen mittels Diagramme visualisieren
- Plausibilitätstest
- Prüfung auf zulässige Werte
- Korrekter Wertebereich: Antwortskala reicht etwa von 0-5; jedoch wurden in manchen Fällen Werte größer 5 angeben
- Inkonsistente Antwortkombinationen: Ein Kind im Alter von 7 Jahren ist Bankangestellter
- Ausreißer bei metrischen Variablen identifizieren und behandeln
- Boxplot und Verteilungsmaße
- Abwägen, ob es sich um plausible Werte handelt und wie mit diesen umgegangen werden soll (löschen, ersetzen, beibehalten)
- (Um)Codieren
- Reihenfolge der Werte ändern
- Von metrischen Variablen in ordinalskalierte Variablen kodieren
- Dummycodierung
- Indikatoren bilden
- Im Bedarfsfall Prüfung der Zulässigkeit (Faktorenanalyse)
- Berechnung einer neuen Variablen
- Voraussetzungen für statistische Verfahren prüfen
- Normalverteilung, Linearität, Homoskedastizität usw.
Wichtig ist folgender Grundsatz bei der Datenbereinigung:
„Auch wenn manche Fehler leicht zu finden und eindeutig zu korrigieren sind, ist der Umgang mit fehlerhaften Werten heikel: Fehlerkorrektur und (zusätzliche) Verfälschung von Daten liegen eng beieinander! Oft gibt es eben nur gute Gründe für die Annahme, der wahre Wert durfte dieser oder jener gewesen sein, aber eben keine Gewissheit“ (Lück, 2011, S. 79f.).
Daher sollte jeder Schritt bei der Aufbereitung genau dokumentiert werden und die Nachvollziehbarkeit auch in die Arbeit als Erörterungen einfließen. Aktuell wird immer häufiger bei Journalpublikationen gefordert, das Datenfile inklusiver aller Arbeitsschritte (von der Aufbereitung und Analyse) offen für Replikationen und damit für die Überprüfung zu stellen.
Damit ist man bei der statistischen Analyse angelangt und führt die geplanten Verfahren durch. Eine vertiefende Besprechung würde den Rahmen an dieser Stelle sprengen, im Weiteren sind ein paar einführende Arbeiten angegeben. Für Anfänger*Innen zuvor noch der Hinweis, dass sich immer eine genaue Dokumentation aller im Statistikprogramm gemachten Schritte empfiehlt. Einerseits können damit Probleme mit Betreuer*Innen leichter besprochen werden, andererseits kann man so sein eigenes Vorgehen auch zu einem späteren Zeitpunkt noch nachvollziehen. In Programm wie SPSS ist eine Analyse mit wenigen „Klicks“ vollzogen und lässt sich mit ein paar weiteren „Klicks“ in den Einstellungen bedeutend verändern, ob dies alles sinnvoll und statistisch korrekt ist, verrät einem das Programm aber nicht.
| Literaturhinweise: |
| Akremi, L., Baur, N., & Fromm, S. (Hrsg.). (2011). Datenanalyse mit SPSS für Fortgeschrittene 1 (3., überarb. u. erw. Aufl). Wiesbaden: VS Verlag für Sozialwissenschaften. |
| Atteslander, P., & Cromm, J. (2008). Methoden der empirischen Sozialforschung (12., durchges. Aufl). Berlin: E. Schmidt. |
| Baur, N., & Fromm, S. (Hrsg.). (2008). Datenanalyse mit SPSS für Fortgeschrittene: ein Arbeitsbuch (2., überarb. und erw. Aufl). Wiesbaden: VS, Verl. für Sozialwiss. |
| Bühl, A. (2016). SPSS 23: Einführung in die moderne Datenanalyse (15., aktualisierte Auflage). Hallbergmoos: Pearson. |
| Döring, N., & Bortz, J. (2016). Forschungsmethoden und Evaluation in den Sozial- und Humanwissenschaften (5. vollständig überarbeitete, aktualisierte und erweiterte Auflage). Berlin Heidelberg: Springer. |
| Fromm, S. (2012). Datenanalyse mit SPSS für Fortgeschrittene 2 : Multivariate Verfahren für Querschnittsdaten (2. Aufl). Wiesbaden: Springer VS. |
| Kromrey, H., Roose, J., & Strübing, J. (2016). Empirische Sozialforschung: Modelle und Methoden der standardisierten Datenerhebung und Datenauswertung mit Annotationen aus qualitativ-interpretativer Perspektive (13., völlig überarbeitete Auflage). Konstanz: UVK Verlagsgesellschaft. |
| Manderscheid, K. (2012). Sozialwissenschaftliche Datenanalyse mit R: eine Einführung (1. Aufl). Wiesbaden: VS, Verl. für Sozialwiss. |
| Rasch, B., Friese, M., Hofmann, W., & Naumann, E. (Hrsg.). (2010a). Quantitative Methoden Band 1: Einführung in die Statistik für Psychologen und Sozialwissenschaftler (3., Aufl). Berlin: Springer. |
| Rasch, B., Friese, M., Hofmann, W., & Naumann, E. (Hrsg.). (2010b). Quantitative Methoden Band 2 : Einführung in die Statistik für Psychologen und Sozialwissenschaftler (3., Aufl). Berlin: Springer. |
| Wollschläger, D. (2017). Grundlagen der Datenanalyse mit R: eine anwendungsorientierte Einführung (4., überarbeitete und erweiterte Auflage). Berlin: Springer Spektrum. |
Die Publikation der Ergebnisse ist das Hauptziel der Forschungsanstrengung, denn nur so lässt sich der Erkenntnisstand in der Scientific Community weiterentwickeln. Grundsätzlich folgt die Struktur einer sekundäranalytischen Arbeit den allgemeinen Regeln empirischer Arbeiten (siehe etwa Jost & Richter, 2015). Um Nachvollziehbarkeit herzustellen ist es zudem wichtig, auf den verwendeten Datensatz sowie die verwendete Version hinzuweisen. Zudem bedarf es einer genauen Beschreibung, welche „Designentscheidungen“ getroffen, d.h. etwa welche Strategien gegenüber Ausreißern oder Gewichtungsverfahren angewandt wurden. Häufig finden sich im Methodenteil der Arbeit auch Angaben zu den Items, anhand derer die verwendeten Daten gewonnen wurden. In manchen Fällen ist der Institution, welche hinter dem Survey steht, ein Exemplar der Arbeit vor der Publikation oder zumindest eine Publikationsangabe zu übermitteln.
Abschließend bleibt noch der Verweis, dass es sich bei Sekundäranalysen um keine Randerscheinung handelt. Roose (2013, S. 702f.) konstatiert bspw. in einer kurzen Analyse, dass in der Kölner Zeitschrift für Soziologie und Sozialpsychologie über 60% der Artikel auf Sekundärdaten basieren. Bis 2008 erschienen alleine auf Basis des Sozioökonomischen Panels (SOEP) über 5.000 Publikationen. Auch wenn mit Sekundärdaten Einschränkungen in Kauf genommen werden müssen, lohnt es sich, mit diesen zu arbeiten, eröffnen sie mit verhältnismäßig einfachen Bedingungen einen Zugang zur empirischen Forschung.
Akremi, L., Baur, N., & Fromm, S. (Hrsg.). (2011). Datenaufbereitung und uni- und bivariate Statistik (3., überarb. u. erw. Aufl). Wiesbaden: VS Verlag für Sozialwissenschaften.
Atteslander, P., & Cromm, J. (2008). Methoden der empirischen Sozialforschung (12., durchges. Aufl). Berlin: E. Schmidt.
Bryman, A. (2012). Social research methods (4th ed). Oxford ; New York: Oxford University Press.
Diekmann, A. (2002). Empirische Sozialforschung: Grundlagen, Methoden, Anwendungen. Reinbek bei Hamburg: Rowohlt.
Diekmann, A. (2016). Empirische Sozialforschung: Grundlagen, Methoden, Anwendungen (10. Auflage, vollständig überarbeitete und erweiterte Neuausgabe August 2007). Reinbek bei Hamburg: rowohlts enzyklopädie im Rowohlt Taschenbuch Verlag.
Döring, N., & Bortz, J. (2016). Forschungsmethoden und Evaluation in den Sozial- und Humanwissenschaften (5. vollständig überarbeitete, aktualisierte und erweiterte Auflage). Berlin Heidelberg: Springer.
Farin, E., Kosiol, D., & Fleitz, A. (2008). Der MOSES-Fragebogen zu Mobilität, Selbstversorgung und häuslichem Leben: Ein ICF-orientiertes Assessmentinstrument, welches in einer Patienten- und einer Behandlerversion vorliegt. Das Gesundheitswesen, 70(07). https://doi.org/10.1055/s-0028-1086472
Hug, T., & Poscheschnik, G. (2015). Empirisch forschen: die Planung und Umsetzung von Projekten im Studium (2., überarbeitete Auflage). Konstanz: UVK Verlagsgesellschaft.
Jost, G., & Richter, L. (2015). Grundlagen wissenschaftlichen Arbeitens: eine prozessbegleitende und reflexive Perspektive. Wien: facultas.
Kromrey, H., Roose, J., & Strübing, J. (2016). Empirische Sozialforschung: Modelle und Methoden der standardisierten Datenerhebung und Datenauswertung mit Annotationen aus qualitativ-interpretativer Perspektive (13., völlig überarbeitete Auflage). Konstanz: UVK Verlagsgesellschaft.
Lück, D. (2011). Mängel im Datensatz beseitigen. In L. Akremi, N. Baur, & S. Fromm (Hrsg.), Datenanalyse mit SPSS für Fortgeschrittene 1 (3., überarb. u. erw. Aufl, S. 66–81). Wiesbaden: VS Verlag für Sozialwissenschaften.
Oswald, F., & Konopik, N. (2015). Bedeutung von außerhäuslichen Aktivitäten, Nachbarschaft und Stadtteilidentifikation für das Wohlbefinden im Alter. Zeitschrift für Gerontologie und Geriatrie, 48(5), 401–407. https://doi.org/10.1007/s00391-015-0912-1
Paier, D. (2010). Quantitative Sozialforschung: eine Einführung (1. Auflage). Wien: facultas.wuv.
Pötschke, M. (2010). Datengewinnung und Datenaufbereitung. In C. Wolf & H. Best (Hrsg.), Handbuch der sozialwissenschaftlichen Datenanalyse (1. Aufl, S. 41–65). Wiesbaden: VS Verlag für Sozialwissenschaften.
Richter, M., & Hurrelmann, K. (Hrsg.). (2009). Gesundheitliche Ungleichheit: Grundlagen, Probleme, Perspektiven (2., aktualisierte Auflage). Wiesbaden: VS Verlag für Sozialwissenschaften.
Richter, M., & Hurrelmann, K. (Hrsg.). (2016). Soziologie von Gesundheit und Krankheit. Wiesbaden: Springer Fachmedien Wiesbaden. Abgerufen von http://link.springer.com/10.1007/978-3-658-11010-9
Roose, J. (2013). Fehlermultiplikation und Pfadabhängigkeit: Ein Blick auf Schattenseiten von Sekundäranalysen standardisierter Umfragen. KZfSS Kölner Zeitschrift für Soziologie und Sozialpsychologie, 65(4), 697–714. https://doi.org/10.1007/s11577-013-0239-0
Saup, W., & Reichert, M. (1999). Die Kreise werden enger. Wohnen und Alltag im Alter. In A. Niederfranke, G. Naegele, & E. Frahm (Hrsg.), Funkkolleg Altern 2: Lebenslagen und Lebenswelten, soziale Sicherung und Altenpolitik. Abgerufen von http://link.springer.com/openurl?genre=book&isbn=978-3-531-13376-8
Schirmer, D. (2009). Empirische Methoden der Sozialforschung: Grundlagen und Techniken. Paderborn: Wilhelm Fink.
Schnell, R. (2012). Survey-Interviews: Methoden standardisierter Befragungen. Wiesbaden: VS, Verlag für Sozialwissenschaften, Springer Fachmedien GmbH.
V.4.0 - 2021